
Let’s be real for a second. In the old days, if you wanted to process a massive CSV file or a stream of logs, you wrote a Python script. You threw it on a Linux box, set up a CRON job, and prayed.If the file got too big? The script crashed (Out of Memory).If the data came in too fast? The CPU choked.
If you needed to process real-time data and historical data? You ended up writing two completely different apps—one for the “live” stuff and one for the “archive.”
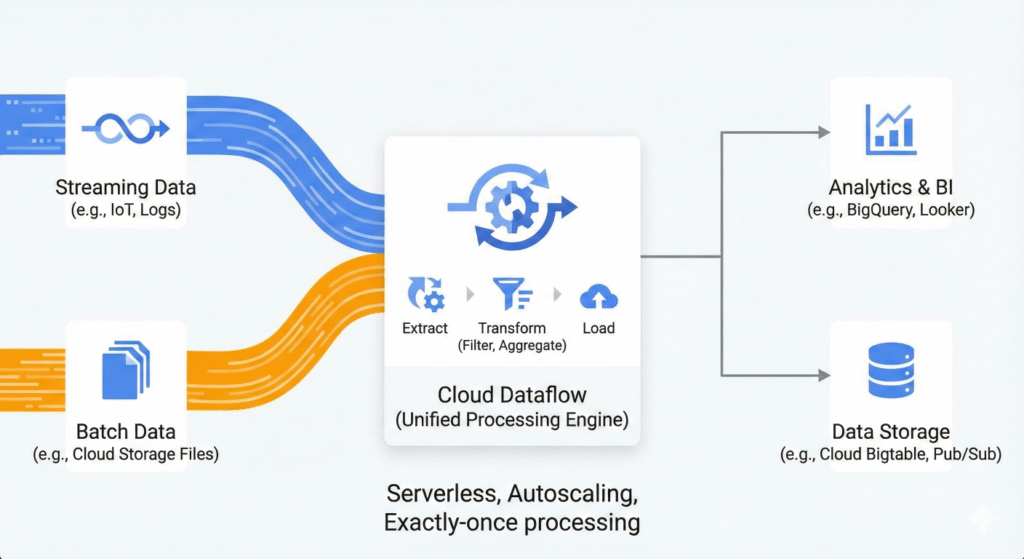
This is the problem Cloud Dataflow solves. It is the “infinite RAM, infinite CPU” machine that runs your logic without you ever touching a server.
What is it, really?
At its core, Dataflow is a managed service for executing Apache Beam pipelines.
Think of it like this:
- Apache Beam is the Blueprint. It’s the open-source SDK (Python, Java, Go) where you define what you want to do (Read data , Filter bad rows ,Sum values ,Write to DB).
- Cloud Dataflow is the Construction Crew. It takes that blueprint, looks at how much work needs to be done, spins up exactly the right number of VMs (workers), does the work, and then shuts everything down.
It is fully Serverless. You don’t provision clusters. You don’t manage Master nodes. You just hand over the job.
How It Works: The Pipeline Lifecycle
From an Architect’s perspective, you need to understand the lifecycle of a Dataflow job because this is where the costs and performance live.
- Graph Construction: When you run your code, Dataflow doesn’t process data immediately. It first reads your code and builds a Directed Acyclic Graph (DAG). It maps out every step (Transform) you asked for.
- Optimization (Fusion): This is the cool part. Dataflow looks at your graph and says, “Hey, step 2, 3, and 4 are all simple math operations. I don’t need to move data between servers for that.” It fuses them into a single step to save time and network overhead.
- Job Submission: The optimized graph is sent to dataflow for processing.
- Autoscaling: Dataflow looks at the input. Is it a 1KB file? It spins up 1 small worker. Is it a 100TB stream? It might spin up 500 workers. It scales horizontally automatically.
- Dynamic Work Rebalancing: If one worker finishes early (maybe it got easy data), Dataflow literally steals work from a slower worker and gives it to the fast one. No worker sits idle.
The Secret Sauce: “Exactly-Once” & Event Time
Why do Architects pick Dataflow over a simple Lambda function? Two words: Correctness and Time.
In distributed systems, things go wrong. A worker crashes. A network packet drops. A mobile phone goes offline and uploads data 4 hours late.
1. Exactly-Once Processing
Dataflow guarantees that every single record is processed exactly once. Not “at least once” (which leads to duplicates), and not “at most once” (which leads to data loss). It handles the deduplication logic for you. For financial data or billing logs, this is non-negotiable.
2. Event Time vs. Processing Time
This is the most critical concept in Dataflow.
- Event Time: When the event actually happened (e.g., User clicked “Buy” at 12:00).
- Processing Time: When the server saw the event (e.g., The log arrived at 12:05 because of network lag).
Dataflow uses Watermarks to track Event Time. It can hold the window open until it is statistically confident that all data from 12:00 has arrived, ensuring your analytics are accurate, even if the network is chaotic.
1. Windows (The Slicer)
Since you can’t process an infinite stream all at once, Windowing chops the stream into finite buckets based on Event Time (when the thing actually happened).1
- Fixed Windows: “Show me the score every 5 minutes.” (0-5, 5-10, 10-15). Simple.
- Sliding Windows: “Show me the average of the last 5 minutes, updated every minute.” (0-5, 1-6, 2-7). Good for trend detection.
- Session Windows: “Group all activity by User X until they stop clicking for 30 minutes.”
- Architect Note: Session Windows are the “Killer App” feature. Doing this in Spark/Dataproc is painful. Dataflow does it natively.
2. Watermarks (The Judge)
This is the hardest concept, but the most important for Data Integrity.
In a distributed system, data arrives out of order. A log from 12:00 might arrive at 12:05 because of network lag. How long does the system wait before it says, “Okay, I think I have all the 12:00 data, let’s calculate the result”?
The Watermark is that heuristic. It is the system’s “confident guess.”
If the Watermark is at 12:05, Dataflow is saying: “I am 99% sure that we have received everything that happened before 12:05. I’m closing the books on that minute.”
- Without Watermarks: You guess. You assume data arrives instantly (it doesn’t).
- With Watermarks: You handle Late Data correctly.
3. Triggers (The Messenger)
If Windows define “What” we group, and Watermarks define “When” we stop waiting, Triggers decide when to yell the answer.
You define triggers to control the trade-off between Completeness and Latency.
- Early Trigger: “Tell me the current count every minute, even if the window isn’t closed yet.” (Fast, but approximate).
- On-Time Trigger: “Tell me the count when the Watermark passes.” (Standard).
- Late Trigger: “If any data arrives after the Watermark (super late), send me an update.” (Correctness backup).
- Windows turn the infinite stream into calculable chunks.
- Watermarks ensure those calculations are accurate, even if the internet is laggy.
- Triggers let you choose if you want the answer fast (Early) or perfect (Late).
Architectural Syntax: A “Pseudo-Code” View
You don’t need to be a programming expert for getting an understanding of Architect’s view but you need to recognize the structure. A Beam/Dataflow pipeline generally looks like this:
Python
import apache_beam as beam
# The "Pipeline" object is the container for the whole workflow
with beam.Pipeline(options=pipeline_options) as p:
(
p
# Step 1: Read (Source)
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(topic=input_topic)
# Step 2: Transform (ParDo = Parallel Do)
| 'JsonParse' >> beam.ParDo(ParseJsonFunction())
# Step 3: Windowing (Group data into 1-minute chunks)
| 'WindowInto' >> beam.WindowInto(window.FixedWindows(60))
# Step 4: Write (Sink)
| 'WriteToBigQuery' >> beam.io.WriteToBigQuery(table_spec)
)
Architect Note: The pipe | character represents the data flowing from one step to the next.
Command Reference: The Architect’s Toolkit
You will likely interact with Dataflow via templates or the CLI during deployments.
| Task | Command | Context |
| Run a Template | gcloud dataflow jobs run <JOB_NAME> --gcs-location=<TEMPLATE_PATH> | Deploy a pre-built Google template (e.g., PubSub to BigQuery) without writing code. |
| List Jobs | gcloud dataflow jobs list | Check status (Running, Failed, Succeeded). |
| Cancel Job | gcloud dataflow jobs cancel <JOB_ID> | Immediate stop. Unprocessed data in flight is lost. |
| Drain Job | gcloud dataflow jobs drain <JOB_ID> | Graceful stop. Finishes processing current buffered data, then stops. |
| Update Job | gcloud dataflow jobs run <JOB_NAME> --update | Updates a streaming job with new code without downtime (must keep same Job Name). |
Pitfalls: Where Architects Fail
I’ve seen plenty of “perfect” architectures fail in production because of these Dataflow specific quirks.
1. The Hot Key Problem (The #1 Killer)
Dataflow scales by sharding data. If you group data by a key (e.g., GroupByKey), and 90% of your data belongs to one key (e.g., Key = “Unknown_User”), all that data goes to one single worker.
- Result: 99 workers sit idle, 1 worker hits 100% CPU and stalls the whole pipeline.
- Fix: Enable Dataflow Shuffle (a backend service that handles the sorting) or randomize keys.8
2. Cost of Streaming
Streaming jobs run 24/7. Even if no data is coming in, you are paying for the persistent disk and the CPU of the minimum worker count.
- Tip: If you don’t need immediate real-time insights, consider a Micro-batch approach (running a Batch job every 15 minutes) to save massive costs.
3. “Wall Time” vs. “CPU Time”
When you look at the bill, you pay for vCPU-hours.
If your code calls an external API (like a database lookup) and waits 500ms for a response, the CPU is idle, but you are still paying for it.
- Fix: Batch your API calls or use
GroupIntoBatchesto reduce network overhead.
4. Regionality
Dataflow is zonal/regional.
- If your bucket is in
us-east1. - And you run Dataflow in
us-west1. - You will pay Cross-Region Data Transfer fees for every byte read. Always co-locate your compute and storage.
Summary
Dataflow is your “set it and forget it” engine for data processing. It unifies batch and stream, handles the chaos of distributed timestamps automatically, and scales from zero to infinity. Just watch out for “Hot Keys” and always check your region settings.
The Emergency Brake vs. The Last Stop: Handling Pipeline Shutdowns
So, you have successfully “sent your graph to the cloud.” The workers are spinning, CPU is burning, and data is flowing.Suddenly, you spot a bug. Or maybe the project manager yells that you’re burning $500/hour and it needs to stop now.
You have two options to stop the machine: Cancel and Drain. As an Architect, knowing the difference is the only thing standing between you and “Corrupted Data.”
1. The “Cancel” (Hard Stop)
Command: gcloud dataflow jobs cancel <JOB_ID>
This is the equivalent of walking over to the server rack and yanking the power cord.
- What happens: The Dataflow service immediately instructs all workers to stop.
- The Data:
- Any data currently in memory (RAM) on the workers is lost.
- Any data that was “half-processed” (e.g., read from Pub/Sub but not yet written to BigQuery) is dropped.
- The Safety Net: Because Dataflow hasn’t “Acknowleged” (Acked) those messages back to Pub/Sub yet, Pub/Sub will eventually redeliver them when you start a new job.
- The Risk: If your pipeline involves non-transactional steps (e.g., “Write to a text file” or “Call an external API”), you might end up with partial data or duplicates (e.g., The API was called, but the job died before it could record that it finished).
Architect’s Verdict: Use
Cancelonly during development/testing or if the pipeline is hopelessly stuck and burning money. Do not use it in Production unless you are okay with cleaning up a mess.
2. The “Drain” (Graceful Shutdown)
Command: gcloud dataflow jobs drain <JOB_ID>
This is the equivalent of putting up a “Closed” sign on the shop door but letting the customers currently inside finish their shopping.
- What happens:
- Ingestion Stops: The pipeline stops pulling new data from the source (e.g., stops reading from Pub/Sub).
- Processing Continues: The workers keep running to process whatever data they have already pulled.
- Windows Close: It waits for any open windows (e.g., “Average of the last 5 minutes”) to finish and emit their results.
- Shutdown: Once all buffers are empty, the job status changes to
Drainedand the VMs shut down.
- The Data: Zero data loss. Everything that entered the pipeline comes out the other side.
- The Cost: You continue to pay for the workers while they “drain.” If you have a huge window (e.g., 24 hours), the job could theoretically take 24 hours to drain!
Architect’s Verdict: Always use
Drainfor Production updates or maintenance. It ensures data consistency.
3. The “Crash” (System Failure)
What if you don’t touch it, but the pipeline crashes on its own (Status: Failed)?
- Scenario: You deploy code that divides by zero.
- Mechanism: Dataflow attempts to retry the failed item 4 times (in Batch) or indefinitely (in Streaming).
- The Result:
- Batch: If it fails 4 times, the entire job fails. Data is not lost (it’s still in the source), but the job stops.
- Streaming: The pipeline might stall indefinitely as it tries to process that one “poison pill” record over and over.
- Architect’s Fix: This is why you need a Dead Letter Queue. You configure the pipeline to say: “If this record fails 4 times, don’t kill the pipeline. Just write this specific record to a special ‘Error Table’ in BigQuery and move on.”
Summary Table
| Scenario | Action | Data Impact | Cost Impact |
| Bad Code / Bug found | Drain | Safe. Finishes current items. | High (pays until finish). |
| Runaway Costs | Cancel | Risk of duplicates/partials. | Stops billing immediately. |
| Update Pipeline | Update (--update) | Seamless. No downtime. | Continuous billing. |
| Job Stuck on 1 item | Fix Code / Dead Letter | Pipeline stalls until fixed. | Burning money while stuck. |
